A frozen VLM. A frozen DiT. A visual page between them.
V2V-Zero replaces text-only user conditioning with final-layer hidden states extracted from visual specification pages. No weight updates. No learned modules. Only a thin inference-time wrapper around interfaces that already exist.
The visual route, already wired.
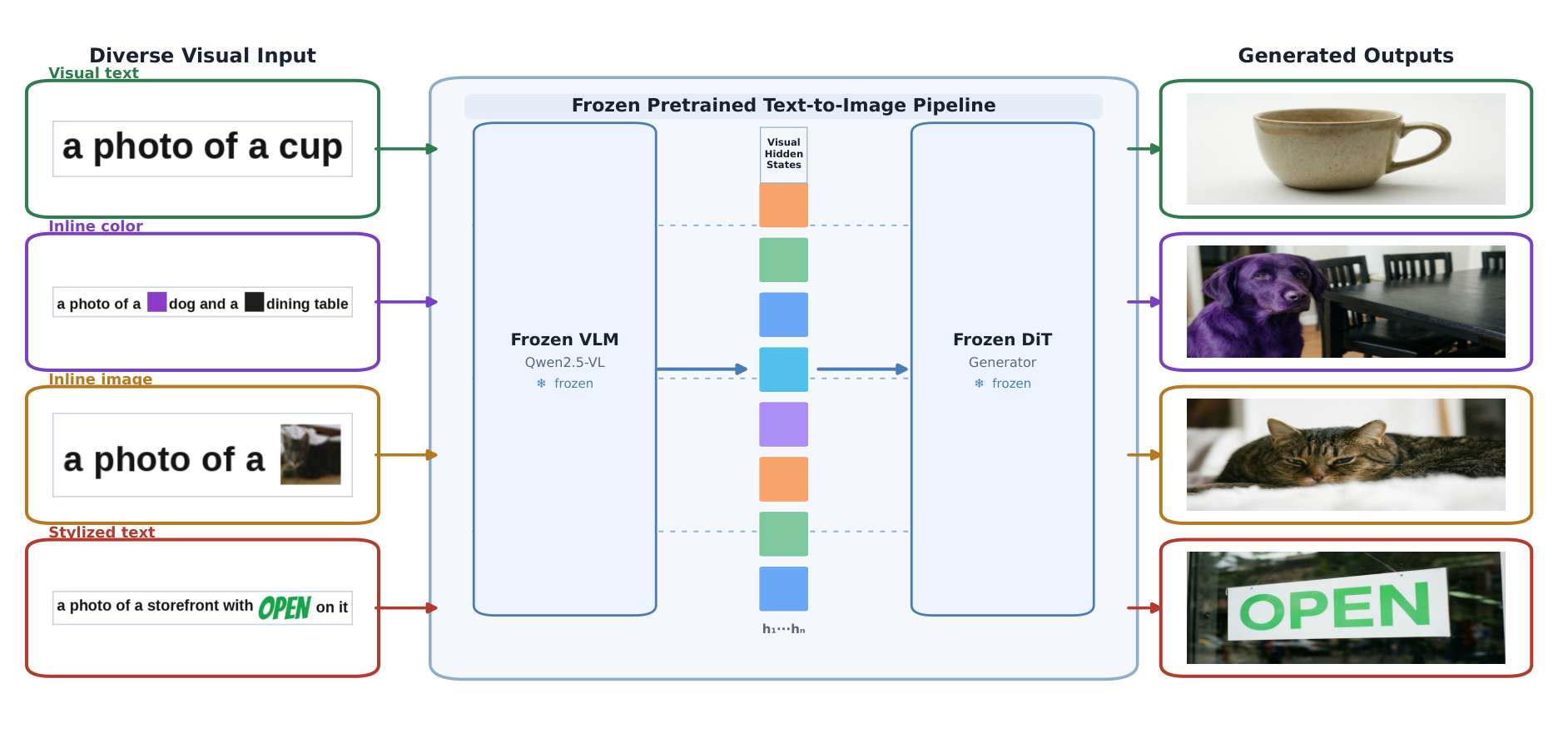
Three steps, zero training.
Compose Visual Page
The user authors a structured visual specification page V ∈ R(H×W×3): spatial diagrams, color swatches, rendered text, or inline thumbnails. The page is not an edit target but a visual document that specifies the desired output.
Encode via Frozen VLM
The visual page is processed by a frozen multimodal VLM encoder E. We extract final-layer hidden states E(V)—the same space the diffusion generator was trained to consume. No additional projector. No new tokens.
Cross-attend & Generate
The frozen diffusion generator G cross-attends to E(V) through its existing conditioning slot and synthesizes I = G(E(V)). The same pipeline lifts directly to video: HunyuanVideo-1.5 injects at the third-from-last VLM layer.
A one-line substitution.
From text to vision, in-place.
In the standard T2I pipeline, text tokens p are encoded by E and the generator yields I = G(E(p)). V2V-Zero observes that E already natively maps visual pages V into the same D-dimensional conditioning space.
Replacing p with V yields V2V-Zero. The user input becomes visual while the generator's learned interface and weights stay unchanged. This is an architectural observation—stating when the pathway exists—not a formal theorem.
Because recent T2I and T2V systems converged on the same VLM-hidden-state-to-diffusion architecture, the same abstraction covers both images and video.
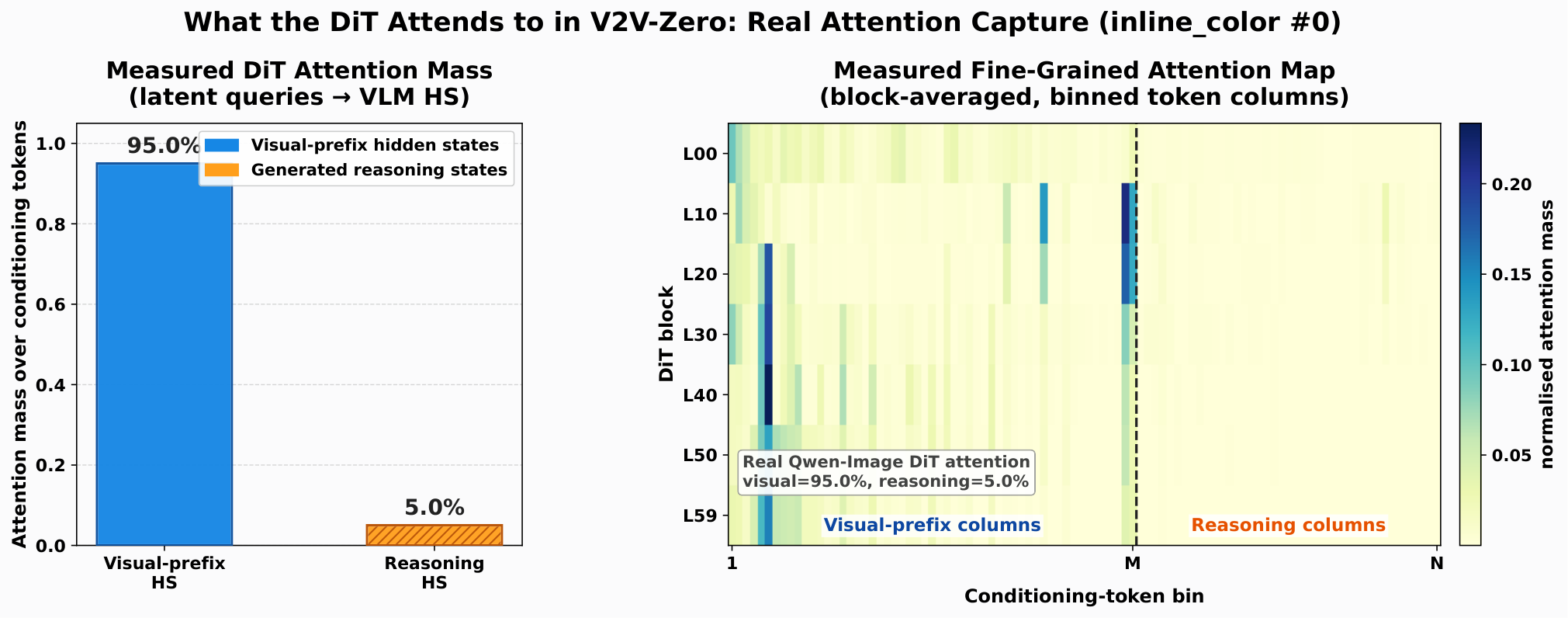
Two hooks. One interface.
Non-reasoning control.
The generator cross-attends only to image-token states from the visual page. This isolates the pure visual signal without any reasoning tokens from the VLM.
Visual states plus reasoning states.
The VLM autoregressively generates reasoning tokens from a fixed prefix. Final-layer hidden states are recomputed under teacher forcing, then injected together with visual states into the DiT conditioning slot.
The generator overwhelmingly reads from the page.
Three families of visual pages.
Compositional Pages
Spatial diagrams that control structured scenes: layouts, blueprints, spatial hierarchies.
Text Pages
Rendered target characters with specified typography, spacing, and visual weight.
Inline Visual Pages
Color swatches and thumbnails embedded within prompt text, binding attribute to object.